

From
www
Get Started for FREE
Sign up with Facebook Sign up with X
I don't have a Facebook or a X account


 Your new post is loading...
Your new post is loading... Your new post is loading...
Your new post is loading...
From
youtu
[For French speakers]
Enseignement 2023-2024 : Apprendre les langues aux machines
Juliette Decugis's insight:
Yann LeCun gives an overview of world-based RL and what are the next big steps for AGI, inspired by his original 2022 paper: https://openreview.net/pdf?id=BZ5a1r-kVsf [in english].
Main take-aways: - learning only from language data is limited and we're reaching the limit with LLMs - models need a world understanding to break down actions hierarchically & plan 
The article discusses the emergence of a non-attention architecture for language modeling, in particular Mamba, which has shown promising results in experimental tests. Mamba is an example of a state-space model (SSM). But what is a state-space model? State-Space Models (SSMs) State-space models (SSMs) are a class of mathematical models used to describe the evolution of […]
Juliette Decugis's insight:
Following on the successes of state space models (S4 and S6), Albert Gu and Tri Dao introduce Mamba (article), a selective SSM which scales linearly with sequence lengths. It achieves state-of-the-art results in language, audio, and genomics compared with same-size and even larger Transformers. Rather than using attention mechanisms for context selection, Mamba relies on state spaces. Unlike previous SSMs, its efficiency and specific GPU design promises speed ups in large scale settings.

Article by David Yastremsky detailing the 2019 Lottery Ticket Hypothesis by Frankle and Carbin’s, a motivating paper for deep learning network sparsification.
Juliette Decugis's insight:
The "lottery ticket hypothesis" shows empirical evidence that the performance of large deep learning models can be reproduced by smaller sub-networks within their architecture. Network pruning is therefore not only possible but can exist at the beginning of training in rare "lottery ticket" cases. Finding these sub-networks could help speed up training, reduce model size and overall help us understand deep learning better.
However, we still haven't found the loophole to train small efficient models from scratch. One key approach for model compression today relies on parent-teacher network where a smaller model learns from the weights of a pre-trained larger model. Many research startups and labs are in the race for scalable generative AI such as Mistral AI and Mosaic ML (recently acquired by Databricks), led by no other than Jonathan Frankle himself.
![[2206.03945] Challenges in Applying Explainability Methods to Improve the Fairness of NLP Models | The Future of Artificial Intelligence | Scoop.it](https://img.scoop.it/u8QC_rM1YADr6siA_SGBuzl72eJkfbmt4t8yenImKBVvK0kTmF0xjctABnaLJIm9)
From
arxiv
"Motivations for methods in explainable artificial intelligence (XAI) often include detecting, quantifying and mitigating bias, and contributing to making machine learning models fairer. However, exactly how an XAI method can help in combating biases is often left unspecified. In this paper, we briefly review trends in explainability and fairness in NLP research, identify the current
Juliette Decugis's insight:
Very relevant paper as large LLMs are raising concerns for AI safety.
As described in this paper, explainability methods have only been applied to ML fairness in narrow applications: for feature understanding and hate speech detection. Although limiting biases is one of the motivations for model transparency, NLP fairness and interpretability struggle to find a common ground.
NLP fairness focuses on local explanations and invariant outcome across groups. On the other hand, XAI aims to solve procedural fairness; whether the model's reasoning across groups is bias. We struggle to generalize local explanations, identify biases without human supervision and quantify how biases may change.
The issue of "fairwashing" is also becoming increasingly concerning as we have no guarantee our current explanation methods actually represent inner working of the model.
At the end of the day, more representative and less bias datasets remain the key to AI fairness.

From
www
Elon Musk among those calling for training in powerful artificial intelligence to be suspended.
Juliette Decugis's insight:
AI experts and industry leaders such as Yoshua Bengio, Stuart Russell, Elon Musk and Steve Wozniak have recently signed an open letter urging AI labs to stop training models larger than GPT-4 for the next six months. They demand a pause for the sake of safety; "Powerful AI systems should be developed only once we are confident that their effects will be positive and their risks will be manageable."
This warning from AI experts has raised concerns from the general public, already fearful of the advancements of AI. Unlike it is portrayed in science fiction, AI isn't taking over the world, today's AI is still very dumb and that's the problem. We have yet to understand how models see patterns in data and therefore how to efficiently train them. The letter signatories denounce the current development of AI; which encourages larger and larger models for enhanced performance rather than theoretical understanding of what these models actually learn.
Let's also take a step back and remember that very few AI labs today have the computational resources to train models as large as GPT-4. This letter is therefore not targeting most current AI research.
Full open letter available here.
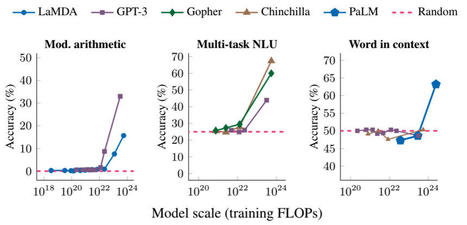
Posted by Jason Wei and Yi Tay, Research Scientists, Google Research, Brain Team The field of natural language processing (NLP) has been revolutionized by language models trained on large amounts of text data.
Juliette Decugis's insight:
This blog highlights recent research by Google, Stanford, UNC and DeepMind on the emergent abilities of large language models specifically on arithmetic and word meaning tasks.
As defined by Wei et al. in their paper, "emergent abilities of large language models as abilities that are not present in smaller-scale models but are present in large-scale models". For example, they observe LLMs such as GPT-3 and PaLM completely fail to learn basic arithmetic tasks until the size of the models reaches 10^22 and we observe a rapid jump in performance.
Comparing implicit models and low scale transformers on very simple arithmetic tasks in my own research, I have also observed transformers poorly extrapolate and therefore fail to learn straightforward additions and multiplications.
I am curious to explore if scalability or multi-step prompting allows for a sudden jump in extrapolation as highlighted in this paper.
More generally, I wonder if we can find new ways to quantify learning to capture the memorization occurring for these tasks prior to the highlighted learning jump.
Will a breakthrough in NLP result in the end of LLM and the beginning of small and as generalizable models? or are LLMs only the start of a much larger beast?
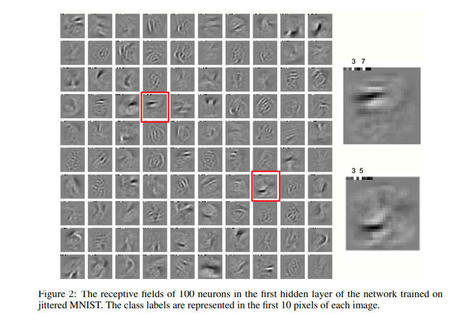
"Hinton proposes the FF algorithm as an alternative to backpropagation for neural network learning."
Juliette Decugis's insight:
At NeurIPS 2022, I had the pleasure of hearing Geoffrey Hinton present his new way for DNN to learn the "forward forward" algorithm. Preliminary work shows good performance on classical benchmarks such as MNIST with less computations and more similarities with our human brain.
Who knows maybe one day similar algorithms will replace good old back propagation?
Full paper, accessible here if you're curious. Hinton also promised to release his code soon so the community can play with it :)
Juliette Decugis's insight:
NeurIPS 2022 poster of the paper:
Dubey A., Radenovic F., Mahajan D., Interpretability via Polynomials, NeurIPS 2022, [arxiv]
which introduces an efficient architecture called Scalable Polynomial Additive Models (SPAM) aiming to balance high expressivity and interpretability. Interesting work that resembles more traditional ML and proposes an alternative to DNNs.

The company's star ethics researcher highlighted the risks of large language models, which are key to Google's business.
Juliette Decugis's insight:
Almost two years ago in December 2020, Timnit Gebru was fired from Google ethical AI team partly for exposing the dangers of Google's large language models (Transformers, BERT, GPT-2 and GPT-3). I found this article interesting because it summarized effectively the four main risks Gebru's paper had highlighted: environmental and financial costs, large training sets which inevitably results in less scrutinization for abusive language & biases, research opportunity costs and illusions of meaning. Those risks are often lost amongst the enthusiasm the AI community has for breaking records on benchmark datasets but they must be at the center of research focus.

"Matrix multiplication is at the heart of many machine learning breakthroughs, and it just got faster—twice. Last week, DeepMind announced it discovered a more efficient way to perform matrix multiplication, conquering a 50-year-old record. This week, two Austrian researchers at Johannes Kepler University Linz claim they have bested that new record by one step."
Juliette Decugis's insight:
Driven by the success of AlphaGo in defeating world champion Go players, Deep Mind researchers redesigned matrix multiplication as a board game, learnable through reinforcement learning. They trained AlphaTensor on this innovative state space. It successfully learned past matrix multiplication techniques and even designed its own, faster by 2 operations. This represents a huge breakthrough for artificial intelligence. It promises first acceleration of deep learning training as even a two step acceleration could lead to hundreds and even thousands less operations on large datasets. On a higher level, these results also demonstrate the capacity of machines to innovate beyond human learning. AlphaGo identified game playing strategies unknown to experts and for the first time GoogleAI was able to generalize this new learning to another domain. This innovation by AlphaTensor later improved on by Austrian researchers promises a future where machine and humans learn from each other.
Link to deep mind article discussing novel matrix multiplication optimization algorithm (AlphaTensor): https://www.deepmind.com/blog/discovering-novel-algorithms-with-alphatensor

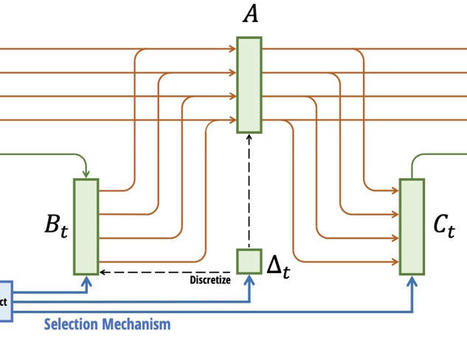
Yann LeCun, machine learning pioneer and head of AI at Meta, lays out a vision for AIs that learn about the world more like humans in a new study.
Juliette Decugis's insight:
In a talk at UC Berkeley this Tuesday, Yann LeCun, one of the founding fathers of deep learning, discussed approaches for more generalizable and autonomous AI.
Current deep learning frameworks require error training to learn very specific tasks and often fail to generalize to even out of distribution input on the same task. Specifically with reinforcement learning, we need a model to "fail" hundreds of times for it to start learning.
As a potential lead away from specialized AI, LeCun proposes a novel architecture composed of five sub-models mirroring the different parts of our brain. Specifically, one of the modules would ressemble memory as a “world model module”. Instead of each model learning a representation of the wold specific to their task, this framework would maintain a world model usable across tasks by different module.
See full paper: https://openreview.net/pdf?id=BZ5a1r-kVsf
Juliette Decugis's insight:
Since the deep learning revolution of the 1990s, AI systems have taken over many different fields. It's easy to view the predictive powers of neural networks as neutral interpretations of data. However, data is subjective and neural networks are subjective.
In this essay, I highlight the limitations of the 2020 California Prop 25 which aimed to replace the cash bail system by a public safety risk score algorithm.
Take a look if you're interested in understanding why such policies could be dangerous.
|
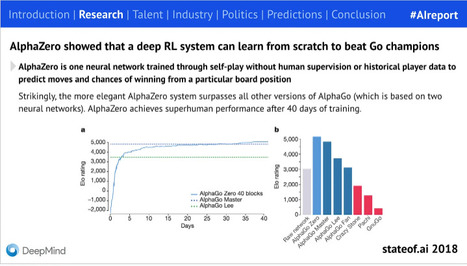
"Introduction The State of AI Report is our comprehensive round-up of the most important developments of the year in AI research, industry, safety, and politics. I started co-producing the report in 2018 with fellow investor Ian Hogarth. After he took on the important role of leading the UK Government’s AI Safety Taskforce, it was a Team Air Street production in 2023." - by Air Street Capital & Nathan Benaich
Juliette Decugis's insight:
From AlphaGo to LLMs with other big innovations such as diffusion models and CLIP, the past five years have seen a rapid boost in AI development through the creation of many private labs, GPU investments by big tech companies and a focus on open source models. This report highlights the key research developments of AI but most interestingly the ecosystem's changes and its societal impacts. High level and easy to read :)
This post is a slightly-adapted summary of two twitter threads, here and here. …
Juliette Decugis's insight:
The new 21st century Turing test :)
![[2303.06349] Resurrecting Recurrent Neural Networks for Long Sequences - Orvieto et al. (ETH & DeepMind) | The Future of Artificial Intelligence | Scoop.it](https://img.scoop.it/b4Wg6QuolUC_Tv4E9P7naTl72eJkfbmt4t8yenImKBVvK0kTmF0xjctABnaLJIm9)
From
arxiv
"Recurrent Neural Networks (RNNs) offer fast inference on long sequences but are hard to optimize and slow to train. Deep state-space models (SSMs) have recently been shown to perform remarkably well on long sequence modeling tasks, and have the added benefits of fast parallelizable training and RNN-like fast inference. [...] Our results provide new insights on the origins of the impressive performance of deep SSMs, while also introducing an RNN block called the Linear Recurrent Unit that matches both their performance on the Long Range Arena benchmark and their computational efficiency."
Juliette Decugis's insight:
All the recent generative AI breakthroughs rely on transformers: OpenAI's GPTs, Meta's Llama, Mistral, Google's Gemini... however they are far from optimal due to their quadratic scaling with sequence length resulting in costly training. In contrast, RNNs scale linearly with sequence length but suffer from exploding and vanishing gradient problems. SSMs on the other hand have shown a lot of potential for modeling long-range dependencies. Orvieto et al., show the performance and efficiency of deep continuous-time SSMs can be matched with a simpler architecture: deep linear RNNs. Using linear hidden state transitions, complex diagonal recurrent matrices and stable exponential re-parametrization, the authors successfully address the failures of RNNs on long sequences. They match S4 results on Path Finder (sequence length = 1024) and Path Finder X (sequence length = 16k). Their reliability on linear recurrent units allows for parallelizable and much faster training.
Overall this paper motivates the search for RNN-based architectures and challenges the Transformer supremacy. SSM models are also emerging as an alternative.
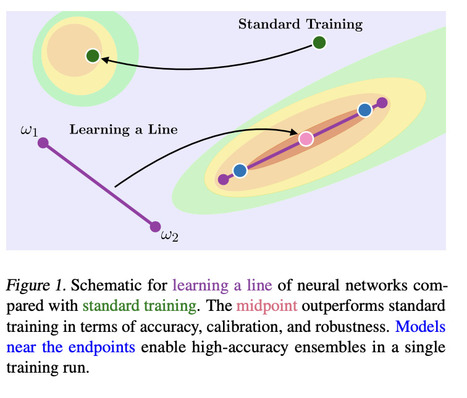
"This work is motivated by the existence of connected, functionally diverse regions in solution space. In contrast to prior work, our aim is to directly parameterize and learn these neural network subspaces from scratch in a single training run. [...] we have trained lines, curves, and simplexes of high-accuracy neural networks from scratch."
Juliette Decugis's insight:
Interesting paper exploring the objective landscape specifically the relationship between subspaces of the loss function where neural networks (here ResNets) converge. Wortsman et al. assume the optimized weights of neural networks are connected through lines, Bezier curves or simplexes during different training iterations. They propose an algorithm to directly learn a connected subspace of the loss function rather than a single set of optimized weights. Their final parameters correspond to the midpoint of this subspace which "can boost accuracy, calibration, and robustness to label noise."
Overall, this paper shows the potential for optimization gains from simple assumptions about the geometry of a network's loss function. It would be worth exploring similar approaches for the weights & subspaces learned within a network.

From
openai
Our mission is to ensure that artificial general intelligence—AI systems that are generally smarter than humans—benefits all of humanity.
Juliette Decugis's insight:
The much criticized statement from OpenAI's president Sam Altman regarding their goals and ethics for the development of AI models.
In short, Altman warns of the risk of AGI if not tested and controlled properly before deployment. He warns that "At some point, it may be important to get independent review before starting to train future systems, and for the most advanced efforts to agree to limit the rate of growth of compute used for creating new models."
While Altman views GPT-4 as a small first step towards a hypothetical AGI future, many AI experts already see the model as dangerous due do its extremely large size and the lack of overall understanding of LLMs.

OpenAI’s latest AI language model has officially been announced: GPT-4. Here’s a rundown of some of the system’s new capabilities and functions, from image processing to acing tests.
Juliette Decugis's insight:
Since the rise of ChatGPT, the world has been waiting for GPT-4, released only two weeks ago!
This articles highlights the new abilities of the model: process images as well as text, better language understanding and enhanced error correction.
These improvements do come at the cost of a bigger model: GPT-4 has 100 trillion parameters approximately 500 times the size of its predecessor GPT-3. The development of larger and larger language models has raised concerns for the future and ethics of AI, is it safe to deploy models we don't fully understand?

Among the great challenges posed to democracy today is the use of technology, data, and automated systems in ways that threaten the rights of the American public. Too often, these tools are used to limit our opportunities and prevent our access to critical resources or services. These problems are well documented. In America and around…
Juliette Decugis's insight:
Motivating to finally see a nation-wide effort to regulate data and AI safety within the US.
Many countries have already implemented policies for data collection regulation specifically the right to know what data is collect and right to erasure. For example, we've seen GDPR (launched 2018) in the EU and even state-wise policies such as California's CCPA (2018).
This blue print for an AI bill of rights encapsulates even more general things from data privacy to algorithm discrimination.
But will this be enough to enable and regulate safer AI?

How did a field born out of mathematics and theoretical computer science join forces with rapid innovation in data and computer systems to change the modern world? What enabled the ML revolution, and what critical problems are left to solve?
Juliette Decugis's insight:
Professor Joseph Gonzales, specialized in ML and data systems, highlights the evolution of the AI field since he was first a graduate student to now. He highlights the change from statistical graphical models to more computationally expensive data driven models.
As someone coming into the field, it's interesting to realize the innovations that enabled and continue to motivate the growth of deep learning.
He highlights key innovations:
According to Prof. Gonzales, the next step in ML is "reliably deploying and managing these trained models to render predictions in real-world settings."
Juliette Decugis's insight:
Recently presented this paper at NeurIPS 2022 workshop on distribution shifts. We demonstrate the higher robustness of implicit models on out of distribution data as compared to classical deep learning architectures (MLP, LSTM, Transformers and Google's Neural Arithmetic Logic Units). We speculate that implicit models, unrestricted in their layer number, can adapt and grow for more complex data.

"Rediet Abebe uses the tools of theoretical computer science to understand pressing social problems — and try to fix them."
Juliette Decugis's insight:
At the 2022 Bay Learn Symposium at Genentech in San Francisco, I had the pleasure of hearing Dr. Rediet Abebe present her work at the intersection of algorithm and social justice. I found Dr. Abebe's work's fascinating as it highlights the possibility of AI for social good and as a tool for greater transparency. Dr. Abebe discussed the growing menace statistical tools such as DNA tests and gunshot detection applications pose on our judicial systems. Indeed, these tools are often used as scientific incontestable proofs in the court room when they haven't gone through sufficient testing. Many of these tools haven't even been peer reviewed by domain experts. Dr. Abebe uses her computer science expertise to expose the flaws of these tools and therefore empower public defenders.
That's only a small portion of her amazing work, take a look at this interview to understand her background and research goals from Dr. Abebe herself.

Alan Turing's Imitation Game has long been a benchmark for machine intelligence. But what it really measures is deception.
Juliette Decugis's insight:
In 1950, Turing designed a simple test to evaluate whether a computer possessed artificial intelligence comparable to humans; a computer must be able to pass as a human during a series of questions.
Today, Google's text generating deep learning models such as GPT-3 easily pass the Turing test. However, whether these models actually understand their generated output or rather excel at combining human text for specific questions stays up for debate.
This article points out the outdated nature of the Turing test to measure NLP advances which is now evaluated on new benchmarks. The Turing test instead raises ethical concerns for AI and its potential for deceit.
It is also interesting to note that NLP models can pass as humans on specific questions but often fail when applied to questions to new domains. Far from resembling human consciousness, current AI remains very specialized and data powered. This motivates the development of new tests to understand model generalization.
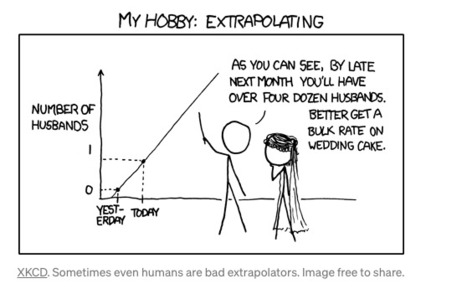
"Models generally cannot extrapolate well, be it in a measure of symbolic intelligence or in real applications."
Juliette Decugis's insight:
As Ye highlights machine learning models are trained to excel at interpolation tasks (predicting within the training distribution) but often fail on extrapolation tasks (predicting outside the training distribution).
During my research with UC Berkeley BAIR, I experimented with sequence extrapolation tasks to compare different models' abilities to understand logical patterns. I witnessed first hand how a simple deviation of the mean in the testing set distribution often led to rapid accuracy drops. Although deep learning models can beat humans at Go and even invent new playing rules, they remain limited in their capacity to use learned skills on a completely new but similar task.
|





My final project report analyzing and evaluating the paper "Low Rank Sinkhorn Factorization" [ICML 2021] by Meyer Scetbon, Marco Cuturi and Gabriel Peyré. Conducted as part of the ENS MVA Mater of Science in the computational optimal transport course by Gabriel Peyré.
Very interesting class to discover optimal transport which can be interpreted as sorting in high dimensions but most concretely as a way to measure the difference between two probability distributions. The mathematical problem of transporting all the information from one distribution to another with minimal cost dates back to the 18th century and today helps design better deep learning models! For example, GANs were made more stable by utilizing transport distances in the adversarial models. There's more direct applications found in NLP for document similarity, shape matching through point cloud distributions and many others in biology.
Specifically, the paper I review presents a new algorithm to efficiently solve a relaxed version of the original optimal transport problem. The authors assume transport between distributions in high dimensions can be broken into independent transports between smaller subsets of each distribution. Key advantages: works with any cost, more interpretable, breaks distributions into low ranks [which could potentially have applications beyond transport solving?]