

Posted by Jason Wei and Yi Tay, Research Scientists, Google Research, Brain Team The field of natural language processing (NLP) has been revolutionized by language models trained on large amounts of text data.
Get Started for FREE
Sign up with Facebook Sign up with X
I don't have a Facebook or a X account


 Your new post is loading...
Your new post is loading... Your new post is loading...
Your new post is loading...
Posted by Jason Wei and Yi Tay, Research Scientists, Google Research, Brain Team The field of natural language processing (NLP) has been revolutionized by language models trained on large amounts of text data. 
No comment yet.
Sign up to comment

Alan Turing's Imitation Game has long been a benchmark for machine intelligence. But what it really measures is deception.
Juliette Decugis's insight:
In 1950, Turing designed a simple test to evaluate whether a computer possessed artificial intelligence comparable to humans; a computer must be able to pass as a human during a series of questions.
Today, Google's text generating deep learning models such as GPT-3 easily pass the Turing test. However, whether these models actually understand their generated output or rather excel at combining human text for specific questions stays up for debate.
This article points out the outdated nature of the Turing test to measure NLP advances which is now evaluated on new benchmarks. The Turing test instead raises ethical concerns for AI and its potential for deceit.
It is also interesting to note that NLP models can pass as humans on specific questions but often fail when applied to questions to new domains. Far from resembling human consciousness, current AI remains very specialized and data powered. This motivates the development of new tests to understand model generalization.

Neural models in recent years have been successful in almost every field including extremely complex problem statements. However, these models are huge in size, with millions (and billions) of…
Juliette Decugis's insight:
A comprehensive introduction to knowledge distillation, a new way to compress neural networks. Neural networks fascinate the machine learning community however there is one issue: they require millions to billions of parameters. Imagine if networks could teach each other reduced versions of their information while achieving the same results.
|
Juliette Decugis's insight:
NeurIPS 2022 poster of the paper:
Dubey A., Radenovic F., Mahajan D., Interpretability via Polynomials, NeurIPS 2022, [arxiv]
which introduces an efficient architecture called Scalable Polynomial Additive Models (SPAM) aiming to balance high expressivity and interpretability. Interesting work that resembles more traditional ML and proposes an alternative to DNNs.
"Models generally cannot extrapolate well, be it in a measure of symbolic intelligence or in real applications."
Juliette Decugis's insight:
As Ye highlights machine learning models are trained to excel at interpolation tasks (predicting within the training distribution) but often fail on extrapolation tasks (predicting outside the training distribution).
During my research with UC Berkeley BAIR, I experimented with sequence extrapolation tasks to compare different models' abilities to understand logical patterns. I witnessed first hand how a simple deviation of the mean in the testing set distribution often led to rapid accuracy drops. Although deep learning models can beat humans at Go and even invent new playing rules, they remain limited in their capacity to use learned skills on a completely new but similar task.

From
medium

I n the world of machine learning, neural network and associated deep learning models are quickly becoming dominant, with very significant amounts of work being published every day, often…
Juliette Decugis's insight:
Implicit Neural Networks, sometimes called deep equilibrium models, aim to represent neural networks as feedforward recursive loops. They provide unique advantages such as higher expressive power, robustness, and interpretability (through their sensitivity matrices).
|





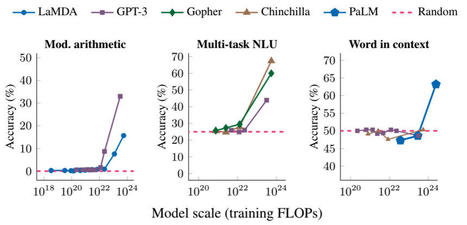
This blog highlights recent research by Google, Stanford, UNC and DeepMind on the emergent abilities of large language models specifically on arithmetic and word meaning tasks.
As defined by Wei et al. in their paper, "emergent abilities of large language models as abilities that are not present in smaller-scale models but are present in large-scale models". For example, they observe LLMs such as GPT-3 and PaLM completely fail to learn basic arithmetic tasks until the size of the models reaches 10^22 and we observe a rapid jump in performance.
Comparing implicit models and low scale transformers on very simple arithmetic tasks in my own research, I have also observed transformers poorly extrapolate and therefore fail to learn straightforward additions and multiplications.
I am curious to explore if scalability or multi-step prompting allows for a sudden jump in extrapolation as highlighted in this paper.
More generally, I wonder if we can find new ways to quantify learning to capture the memorization occurring for these tasks prior to the highlighted learning jump.
Will a breakthrough in NLP result in the end of LLM and the beginning of small and as generalizable models? or are LLMs only the start of a much larger beast?